星型模式(star schema)是在學校學習數據建模和數據庫設計時的經典模型。
以下是模式的簡單解釋:
1. 數據庫模式(database schema):它展示了在關聯數據庫中數據如何使用鍵相互關聯的設計。
2. 一對多關係(1 to many relationship):這說明了兩個表之間的關係,其中它們都有一個共同的列,我們稱之為“鍵”。在這種關係中,一個表的行中有唯一、不重複的鍵(“一”表示這種關係),而另一個表的行中有重複的鍵(“多”表示這種關係)。
例如,銷售訂單表中可能包含相同的客戶多次,因為客戶下多個訂單。客戶表只包含每行1個客戶名稱,因為它包含客戶數據,每個客戶數據都是唯一的。
維度資料表(Dimension table):這些表的鍵是唯一且不重複的,例如日期、產品、銷售等。
事實表格(fact table):這些表的鍵是重複的且不唯一的。通常包含歷史記錄或實際信息表。示例包括交易表、廣告成本表等。
星型模式(star schema):這是一種設計,其中有一個事實表與多個具有一對多關係的維度表相關聯。連接看起來有點像一顆星星。
在現實世界中,一家公司的數據庫通常包含多個事實表,因為信息來自多種不同的來源和平台。因此,對於多樣化和動態的儀表板,設計星型模式幾乎是不可能的。
我想與大家分享一些建模的技巧和訣竅,以確保你的模式設計不會出現歧義。
Tip #1
雙向關係:在沒有交叉篩選(bidirectional filtering)問題的情況下使用雙向關係(bidirection relationship),否則你將使PowerBI在報告中兩次篩選表格,導致計算出現問題。
雙向關係將導致數據建模中的歧義,並導致交叉過濾。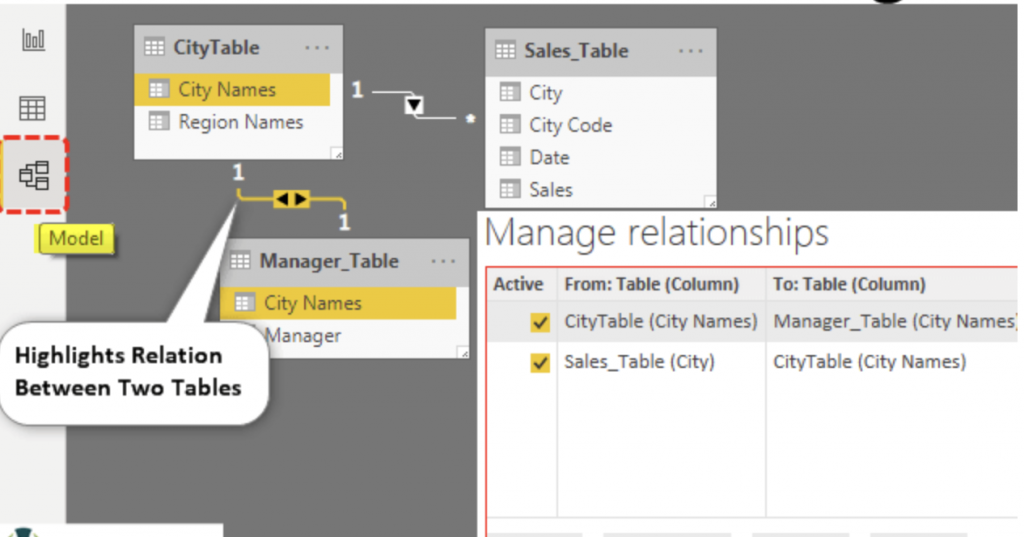
Tip #2
有一個主維度資料表(Dimension table)來接事實表格(fact table),且用它來連其他維度資料表。
在PowerBi中,對維度的雙向連接將自動導致1個連接被停用。
解決方法之一是只保留1個主維度資料表,然後用它來連所有的事實表格。請確保建立的關係不是雙向的(參見下面的截圖)。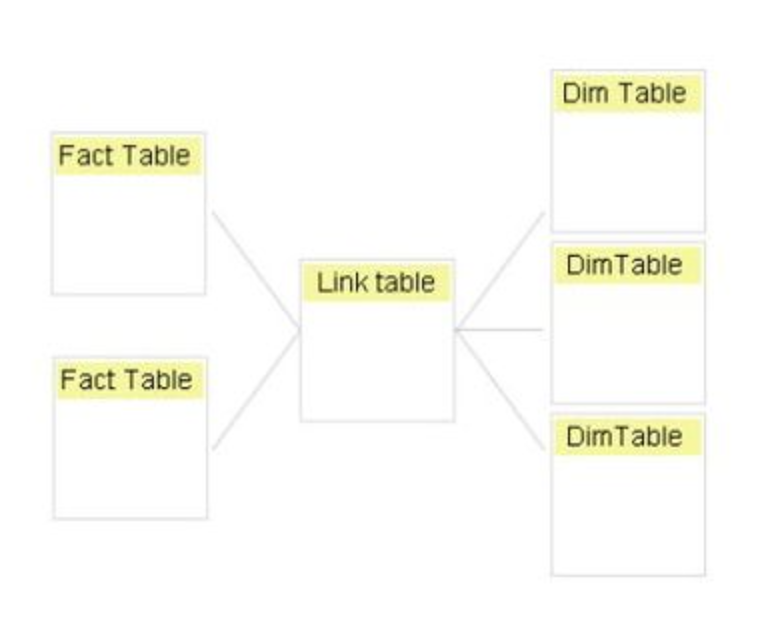
Tip #3
只保留你需要的行列
有時,當你需要為多個事實表格(fact tables)設計模型時,你會覺得保留原先數據裡有的行列以免以後要用。可是這樣做只會導致模型載入時間更長,使數據轉換更慢。所以,我建議只保留你實際要用的行列就好。
希望這些技巧能幫助你打下Powerbi模式設計的良好基礎。
對 dbt 或 data 有興趣 :wave:?歡迎加入 dbt community 到 #local-taipei 找我們,也有實體 Meetup 請到 dbt Taipei Meetup 報名參加


 iThome鐵人賽
iThome鐵人賽